C# - Audio - File RIFF
C#
Audio - I File RIFF
Generalità
- Il formato RIFF dei file è un formato generico per la memorizzazione di diversi tipi di dati, tipicamente multimediali (audio, video) ma non solo.
- Alcune estensioni tipiche riguardano i file audio wave (estensione wav) e i file video avi (estensione avi).
- Per una descrizione dettagliata, Internet offre moltissime fonti.
Formato dei file RIFF
- I file RIFF sono costituiti da blocchi chiamati 'chunk' che possono essere anche contenuti gli uni dentro gli altri. La struttura dei file è quindi gerarchica e in certi casi può essere anche piuttosto complessa.
- I chunk hanno sempre il seguente formato:
- 4 byte 'Chunk ID': è una stringa che identifica il chunk.
- 4 byte 'Chunk Size': con la lunghezza del blocco dati successivo, rappresentata in formato 'little-endian'.
- N byte 'Chunk Data': (vedi il campo precedente) con il blocco dati.
- 1 byte 'Pad': opzionale di riempimento se il chunk non ha una lunghezza pari.
- Se l'ID del chunk è 'RIFF' o 'LIST', allora il blocco dati contiene uno o più sub-chunk e i primi 4 byte (del blocco dati) contengono il codice (è una stringa) che rappresenta il tipo di dati. Questo campo è detto 'Format Type'.
- In un file RIFF, il primo chunk deve essere di tipo 'RIFF'. Tutti gli altri chunk, sono sub-chunk.
- Anche i sub-chunk possono essere di tipo 'LIST', aumentando di un livello la gerarchia dei dati contenuti.
Esempio
- L'esempio seguente mostra l'organizzazione dei chunk di un file RIFF con estensione avi, quindi di un file video.
RIFF (AVI) chunk di 1° livello
LIST (hdrl) chunk di 2° livello
avih chunk di 3° livello
LIST (strl) chunk di 3° livello
strh chunk di 4° livello
strf chunk di 4° livello
JUNK chunk di 2° livello
LIST (movi) chunk di 2° livello
00db chunk di 3° livello
00dc chunk di 3° livello
00dc chunk di 3° livello
00db chunk di 3° livello
00dc chunk di 3° livello
00dc chunk di 3° livello
00db chunk di 3° livello
00dc chunk di 3° livello
00dc chunk di 3° livello
00db chunk di 3° livello
00dc chunk di 3° livello
00dc chunk di 3° livello
00db chunk di 3° livello
00dc chunk di 3° livello
00dc chunk di 3° livello
idx1 chunk di 2° livello
- Per i chunk con ID 'RIFF' e 'LIST', tra parentesi è indicato il 'Format Type'. Per esempio il chunk principale ha formato 'AVI', mentre il primo chunk di tipo 'LIST' ha formato 'hdrl'.
Una vista in esadecimale
- Nella figura seguente, c'è una vista della parte iniziale di un file AVI aperto con un editor esadecimale.
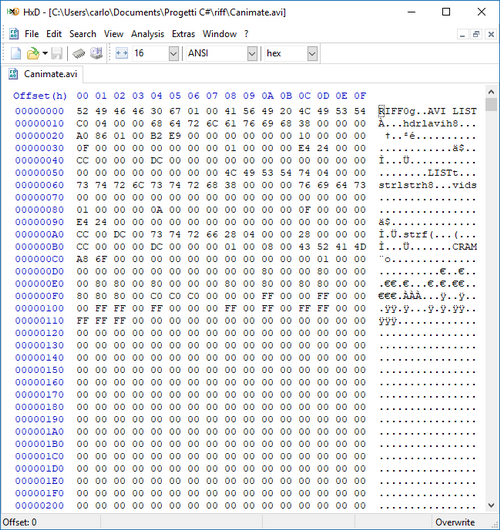
- Si analizzano ora i byte descritti in precedenza. Attenzione: sono tutti in esadecimale, applicare quindi le dovute conversioni.
- 'Chunk ID': Nella figura seguente sono evidenziati i primi 4 byte del chunk principale. Sono i byte 52h, 49h, 46h e 46h che rappresentano i quattro byte 'R', 'I', 'F', e 'F'.

- 'Chunk Size': Nella figura seguente sono evidenziati i 4 byte del chunk principale che rappresentano la dimensione del 'Chunk Data'. Essendo in formato 'little-endian', il primo è il meno significativo. La dimensione del 'Chunk Data' è quindi 30h + 67h*256 + 01h*256^2; convertendo in decimale: 48 + 103*256 + 1*256^2 = 91.952 byte.

- 'Chunk Data': Nella figura seguente sono evidenziati i primi byte del 'Chunk Data' che ha una dimensione variabile. Essendo il Chunk di tipo 'RIFF', contiene a sua volta dei sub-chunk e i primi 4 byte sono il 'Format Type', in questo esempio 'AVI ' (si noti lo spazio dopo la scritta 'AVI', in quanto anche questo campo è lungo 4 byte).

Audio - Decodificare i file RIFF
Obiettivo
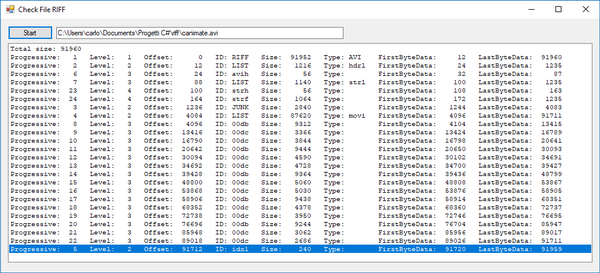
- Con il progetto seguente, si vuole estrarre da un file RIFF tutti i chunk. Per ognuno di essi si vuole conoscere l'ID, l'offset (cioè il byte di inizio chunk) e gli indirizzi di inizio e fine del blocco dati.
- Questo progetto ha una semplice form con i seguenti oggetti:
- Un Button che lancia la decodifica, btnStart.
- Una TextBox dove si scrive il nome del file da decodificare, txtFile.
- Una ListBox dove si scrive l'esito della decodifica, lstInfo. In questa ListBox si è impostato un Font monospace (per esempio Courier New) al fine di allineare i messaggi e renderli più leggibili.
Classi e metodi utili
- Il progetto necessita - oltre alla classe principale, 'Form1' derivata da 'Form' - anche di un paio di classi aggiuntive e di alcuni metodi.
- La prima di queste è la classe 'Chunks'. Ogni proprietà è commentata ed è di immediata comprensione, eccetto la proprietà 'HasSubChunks' che indica la presenza di sub-chunk ancora da elaborare. Al termine dell'esecuzione del programma, questa proprietà sarà 'false' per tutti gli oggetti.
public class Chunks
{
public int Progressive { get; set; } // Identificatore univoco del chunk.
public int Offset { get; set; } // Indirizzo di inizio chunk.
public string ID { get; set; } // ID del chunk.
public int Size { get; set; } // Dimensione del chunk.
public string FormatType { get; set; } // Tipo del chunk (solo per RIFF e LIST).
public bool HasSubChunks { get; set; } // True se contiene dei subchunk da elaborare.
public int FirstByteData { get; set; } // Indirizzo del primo byte della zona dati.
public int LastByteData { get; set; } // Indirizzo dell'ultimo byte della zona dati.
public int Level { get; set; } // Livello del chunk.
}
- La logica del programma necessita anche di una ulteriore classe temporanea, che viene utilizzata per calcolare il livello di profondità di un chunk. Si ricordi infatti che i chunk di un file RIFF hanno una struttura gerarchica. Ecco quindi la classe 'ChunkTemp'.
public class ChunkTemp
{
public int Progressive { get; set; } // Identificatore univoco del chunk.
public int Offset { get; set; } // Indirizzo di inizio/fine chunk.
public string TipoIndirizzo { get; set; } // "I" se inizio, "F" se fine.
}
- Il metodo seguente è utilizzato per l'inserimento di un messaggio nella ListBox.
private void AddMessageToList(string msg)
{
lstInfo.Items.Add(msg);
lstInfo.SelectedIndex = lstInfo.Items.Count - 1;
}
- Le dimensioni dei dati sono rappresentate con 4 byte in formato 'little-endian'. I metodi seguenti convertono i 4 byte in formato 'little-endian' e 'big-endian' in un numero intero. Nel progetto è utilizzato solo il primo metodo, mentre il secondo è riportato per completezza.
int GetBigEndianIntegerFromByteArray(byte[] data, int startIndex)
{
return (data[startIndex] << 24)
| (data[startIndex + 1] << 16)
| (data[startIndex + 2] << 8)
| data[startIndex + 3];
}
int GetLittleEndianIntegerFromByteArray(byte[] data, int startIndex)
{
return (data[startIndex + 3] << 24)
| (data[startIndex + 2] << 16)
| (data[startIndex + 1] << 8)
| data[startIndex];
}
Organizzazione del progetto
- Il progetto ha le seguenti variabili globali alla classe:
- progressive: è un codice univoco associato al chunk.
- lstChunks: è la lista degli oggetti di tipo Chunks.
- La classe form (nome 'form1') ha il codice seguente, si riporta solo la dichiarazione dei metodi / eventi, per spiegare l'organizzazione della classe; il codice intero è riportato nei successivi paragrafi.
public partial class Form1 : Form
{
int progressive = 1; // Codice univoco del chunk.
List<Chunks> lstChunks = new List<Chunks>();
public Form1()
{ }
private void btnStart_Click(object sender, EventArgs e)
{ }
private void ProcessChunk(FileStream fsRead, int firstByte, int lastByte)
{ }
private void SetLevels()
{ }
private void ShowChunks(int fileDimension)
{ }
int GetBigEndianIntegerFromByteArray(byte[] data, int startIndex)
{ }
int GetLittleEndianIntegerFromByteArray(byte[] data, int startIndex)
{ }
private void AddMessageToList(string msg)
{ }
}
- Si noti, in sequenza:
- La dichiarazione delle variabili di classe.
- Il costruttore della form.
- L'evento associato al Click del Button.
- Il metodo ProcessChunk().
- Il metodo SetLevels().
- Il metodo ShowChunks().
- Il metodo GetBigEndianIntegerFromByteArray(), già descritto.
- Il metodo GetLittleEndianIntegerFromByteArray(), già descritto.
- Il metodo AddMessageToList(), già descritto.
Il costruttore del form
- Il codice del costruttore del form è quello di default.
public Form1()
{
InitializeComponent();
}
L'evento associato al Click del Button
- Il codice è il seguente:
private void btnStart_Click(object sender, EventArgs e)
{
using (FileStream fsRead = new FileStream(@txtFile.Text, FileMode.Open))
{
int fileDimension = (int)fsRead.Length;
byte[] buffer = new byte[0]; // Buffer di lettura.
int read = 0; // Numero di byte letti.
AddMessageToList(String.Format("Total size: {0}", fileDimension.ToString()));
// FourCC.
fsRead.Seek(0, SeekOrigin.Begin);
buffer = new byte[4];
read = fsRead.Read(buffer, 0, 4);
string fourCC = Encoding.UTF8.GetString(buffer);
if (fourCC == "RIFF")
{
// Size.
fsRead.Seek(4, SeekOrigin.Begin);
buffer = new byte[4];
read = fsRead.Read(buffer, 0, 4);
int size = GetLittleEndianIntegerFromByteArray(buffer, 0);
// Format Type.
fsRead.Seek(8, SeekOrigin.Begin);
buffer = new byte[4];
read = fsRead.Read(buffer, 0, 4);
string formatType = Encoding.UTF8.GetString(buffer);
Chunks sc = new Chunks();
sc.Progressive = progressive;
sc.Offset = 0;
sc.ID = fourCC;
sc.Size = size;
sc.FormatType = formatType;
sc.HasSubChunks = true;
sc.FirstByteData = 12;
sc.LastByteData = fileDimension;
sc.Level = 0;
lstChunks.Add(sc);
// Elabora i subchunks.
while (lstChunks.Count(p => p.HasSubChunks == true) > 0)
{
Chunks c = lstChunks.First(p => p.HasSubChunks == true);
ProcessChunk(fsRead, c.FirstByteData, c.LastByteData);
c.HasSubChunks = false;
}
// Imposta il livello.
SetLevels();
// Ordina i chunk.
lstChunks = lstChunks.OrderBy(p => p.Offset).ToList();
// Mostra i risultati.
ShowChunks(fileDimension);
}
}
}
- Si noti, in sequenza:
- L'apertura del file e il calcolo della sua dimensione.
- L'identificazione dei primi 4 byte; il codice non produce alcun risultato se i byte non corrispondono alla sigla 'RIFF'.
- L'identificazione della dimensione del blocco dati.
- L'identificazione del formato.
- L'aggiunta del chunk principale alla lista dei chunk.
- Un ciclo 'while' attraverso la lista dei chunk, che richiama il metodo 'ProcessChunk' per tutti i chunk che hanno la proprietà 'HasSubChunks' uguale a true. Il metodo 'ProcessChunk, man mano che procede, può generare altri sub-chunk.
- Al termine del ciclo while, tutti i chunk sono stati estratti.
- Per tutti i chunk, si calcola il livello di profondità con il metodo 'SetLevels()'
- I chunk vengono ordinati.
- Tutti gli attributi rilevanti dei chunk, sono mostrati nella lista con il metodo 'ShowChunks()'.
Il metodo ProcessChunk()
- Il codice è il seguente:
private void ProcessChunk(FileStream fsRead, int firstByte, int lastByte)
{
byte[] buffer = new byte[0]; // Buffer di lettura.
int read = 0; // Numero di byte letti.
int position = firstByte; // Posizione generica nel file.
bool hasSubChunks = false; // Il chunk, contiene dei subchunk.
int firstByteData = 0; // Offset dei subchunks.
int lastByteData = 0; // Ultimo byte dei subchunks.
while (position < lastByte)
{
// FourCC.
fsRead.Seek(position, SeekOrigin.Begin);
buffer = new byte[4];
read = fsRead.Read(buffer, 0, 4);
string fourCC = Encoding.UTF8.GetString(buffer);
// Size.
fsRead.Seek(position + 4, SeekOrigin.Begin);
buffer = new byte[4];
read = fsRead.Read(buffer, 0, 4);
int size = GetLittleEndianIntegerFromByteArray(buffer, 0);
// Type.
string type = String.Empty;
if (fourCC == "RIFF" || fourCC == "LIST")
{
fsRead.Seek(position + 8, SeekOrigin.Begin);
buffer = new byte[4];
read = fsRead.Read(buffer, 0, 4);
type = Encoding.UTF8.GetString(buffer);
hasSubChunks = true;
firstByteData = position + 12;
lastByteData = firstByteData + size - 5;
}
else
{
hasSubChunks = false;
firstByteData = position + 8;
lastByteData = firstByteData + size - 1;
}
// Nuovo Chunk.
Chunks sc = new Chunks();
progressive++;
sc.Progressive = progressive;
sc.Offset = position;
sc.ID = fourCC;
sc.Size = size;
sc.FormatType = type;
sc.HasSubChunks = hasSubChunks;
sc.FirstByteData = firstByteData;
sc.LastByteData = lastByteData;
sc.Level = 0;
lstChunks.Add(sc);
position = lastByteData + 1;
// Eventuale pad alla word successiva.
if (lastByteData % 2 == 0)
position++;
}
}
- Il metodo è chiamato ogni volta che un'area dati contiene sub-chunk.
- Il metodo prende come argomenti oltre al file che si sta elaborando, anche gli indirizzi dell'area di memoria del chunk stesso.
- Si identificano in sequenza: l'ID del chunk, la dimensione e l'eventuale Format Type.
- Infine si inserisce nella lista dei chunk, il chunk appena ottenuto, con l'accortezza di impostare la proprietà HasSubChunks a true se si sta elaborando un chunk che contiene sub-chunk.
Il metodo SetLevels()
- Il codice è il seguente:
private void SetLevels()
{
List<ChunkTemp> lstTemp = new List<ChunkTemp>();
// Preparazione lstTemp.
foreach (var c in lstChunks)
{
ChunkTemp t1 = new ChunkTemp();
t1.Progressive = c.Progressive;
t1.Offset = c.FirstByteData;
t1.TipoIndirizzo = "I";
lstTemp.Add(t1);
ChunkTemp t2 = new ChunkTemp();
t2.Progressive = c.Progressive;
t2.Offset = c.LastByteData;
t2.TipoIndirizzo = "F";
lstTemp.Add(t2);
}
// Si ordina la lista per l'Offset.
List<ChunkTemp> lstOffset = lstTemp.OrderBy(p => p.Offset).ToList();
// Si imposta il Level.
int level = 0;
for (int i = 0; i < lstOffset.Count; i++)
{
if (lstOffset[i].TipoIndirizzo == "I")
{
level++;
Chunks c = lstChunks.Where(p => p.Progressive == lstOffset[i].Progressive).First();
c.Level = level;
}
else
{
level--;
}
}
}
- Si utilizza la classe 'ChunkTemp'. Si inseriscono in questa classe due oggetti per ogni chunk presente nella lista. Il primo oggetto è marcato come "I" (inizio), il secondo come "F" (fine).
- Si ordina quindi la lista 'lstOffset' che contiene gli oggetti 'ChunkTemp'.
- Si calcola il livello di ogni chunk con l'algoritmo:
- Si cicla la lista degli offset.
- Se si incontra un offset di inizio chunk, si incrementa il livello del chunk in elaborazione e lo imposta.
- Se si incontra un offset di fine chunk, si decrementa il livello del chunk in elaborazione.
Il metodo ShowChunks()
- Il codice è il seguente:
private void ShowChunks(int fileDimension)
{
int maxDigits = fileDimension.ToString().Length + 1;
for (int i = 0; i < lstChunks.Count; i++)
{
Chunks c = lstChunks[i];
StringBuilder s = new StringBuilder();
s.Append("Progressive: " + c.Progressive.ToString().PadLeft(3));
s.Append(" ");
s.Append("Level: " + c.Level.ToString().PadLeft(3));
s.Append(" ");
s.Append("Offset: " + c.Offset.ToString().PadLeft(maxDigits));
s.Append(" ");
s.Append("ID: " + c.ID);
s.Append(" ");
s.Append("Size: " + c.Size.ToString().PadLeft(maxDigits));
s.Append(" ");
s.Append("Type: " + c.FormatType.PadLeft(4));
s.Append(" ");
s.Append("FirstByteData: " + c.FirstByteData.ToString().PadLeft(maxDigits));
s.Append(" ");
s.Append("LastByteData: " + c.LastByteData.ToString().PadLeft(maxDigits));
AddMessageToList(s.ToString());
}
}
- Semplicemente, scrive nella lista gli attributi di tutti i chunk.
- Ecco il risultato: